Pix2Pix의 가장 큰 한계점은 뭘까요? 바로 Paired Dataset이 필요하다는 점입니다. 예를 들어 흑백 영상에 색을 입히는 Colorization Method의 경우 흑백 영상과 이에 대응하는 Color 영상이 필요합니다. 이러한 문제들의 경우 Paired Data를 생성하는 것이 쉽습니다. Color 영상만 있으면 이로부터 쉽게 흑백 영상을 얻을 수 있기 때문입니다. 하지만 영상 속 사람의 성별을 바꾸는 알고리즘, 나이를 바꾸는 알고리즘들은 어떨까요? 특정 사람의 데이터를 갖고 있다고 해도, 그 사람의 성별이 바뀐 상태 또는 몇십년 후나 전의 영상 데이터를 얻기란 쉽지 않습니다. 이렇게 Paired Data를 얻기가 쉽지 않은 경우에 대해서도 영상의 Style Transfer를 가능하게 한 GAN 알고리즘이 바로 DiscoGAN입니다. DiscoGAN과 매우 유사한 방식의 알고리즘인 CycleGAN도 있는데, 이 포스트에서는 DiscoGAN을 위주로 설명 드리도록 하겠습니다. CycleGAN에 관해서는 참고 논문에 링크를 올릴 테니 참고 부탁드립니다.
- 선수 지식: 이 포스트를 이해하기 위해서는 Pix2Pix에 대한 지식이 필요합니다.
- 참고 논문: Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
- CycleGAN 논문: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- 소스 코드: Tensorflow_DiscoGAN
Pix2Pix로 해결 불가능한 문제들
Pix2Pix를 학습시키기 위해서는 input으로 들어갈 dataset과 그 이미지들이 Pix2Pix를 거쳐서 나올 정답 이미지가 필요하다. 즉 Supervised Learning 알고리즘이다. 이전 포스팅에서 Pix2Pix는 이러한 Paired Data를 얻기 쉬운 상황에서는 충분한 가치를 지닌 알고리즘이라고 소개하였지만, 역시 그렇지 못한 경우에는 힘을 발휘하지 못한다. 다음 예를 보도록 하자.

그림1은 주어진 사진의 계절을 바꿔주는 알고리즘이다. 여름 풍경을 겨울의 풍경으로 바꿔주거나 겨울 풍경을 여름 풍경으로 바꿔준다. 이 경우 Pix2Pix를 이용한 구현이 가능할까? 그러기 위해서는 같은 장소에 대한 여름과 겨울 이미지가 전부 갖춰진 Paired Dataset이 필요하다. 뭐 아주 불가능한 건 아니다. 여름에 찍은 풍경을 겨울까지 기다린 다음 다시 찍으면 되는 일이니까. 하지만 굉장히 까다로운 것은 사실이다.

그렇다면 그림2는 어떨까? 얼룩말의 사진을 주면 사진 속 얼룩말들과 똑같은 생김새에 똑같은 자세를 취하고 있는 말로 바꿔준다. 반대방향도 마찬가지다. 이 경우 Pix2Pix로 구현하기 위해서는 얼룩말 사진을 찍고, 똑같은 체구의 말들을 데려와서 같은 자세를 취하게 한 후 사진을 찍어 줘야 겨우 하나의 Paired Data를 얻을 수 있다. 물론 이 경우도 정말 완전히 불가능한 경우는 아니라고 생각하시는 분이 계실 것이다. 그렇다면 다음 그림을 보자.

그림3은 주어진 사진을 각각 과거의 유명한 화가들의 화풍을 담은 그림으로 그려내는 알고리즘이다. Style Transfer라고도 한다. 안타깝게도 이 위대한 화가들께서는 이미 돌아가셨으며, 설령 살아계시는 화가들의 화풍으로 바꾼다고 해도, Paired Data를 만들기 위해 이 분들을 고용해야 한다는 큰 어려움이 따른다. 이렇듯 Pix2Pix로는 해결하지 못하는 다양한 Image Translation 문제들이 존재한다. DiscoGAN 알고리즘이 이를 어떻게 해결하는 지 다음 장에서 살펴보도록 하자.
DiscoGAN 알고리즘
위의 예시들 중 그림2의 얼룩말과 말의 문제를 예시로 생각해보자. 사람의 경우, 분명히 말들과 얼룩말들이 각각 어떻게 생겼는지를 학습하는 것 만으로도 주어진 이미지 속 말과 같은 생김새의 얼룩말을 떠올리는 것이 가능하다. 즉, 말과 비슷한 생김새 & 같은 자세의 얼룩말을 보여줘야지 비로소 상상이 가능하거나 하지 않는다.
컴퓨터 또한 같은 자세의 말과 얼룩말 데이터를 보지 않고, 말과 얼룩말이 각각 어떻게 생겼는지만 보고도 학습이 가능해야 한다. 즉, 같은 자세로 짝지어진 데이터가 아닌, 단순히 말들의 이미지와 얼룩말들의 이미지만 가지고 학습이 가능해야 한다. 논문에서는 이를 가능하게 하기 위해 다음과 같은 구조를 제안한다.
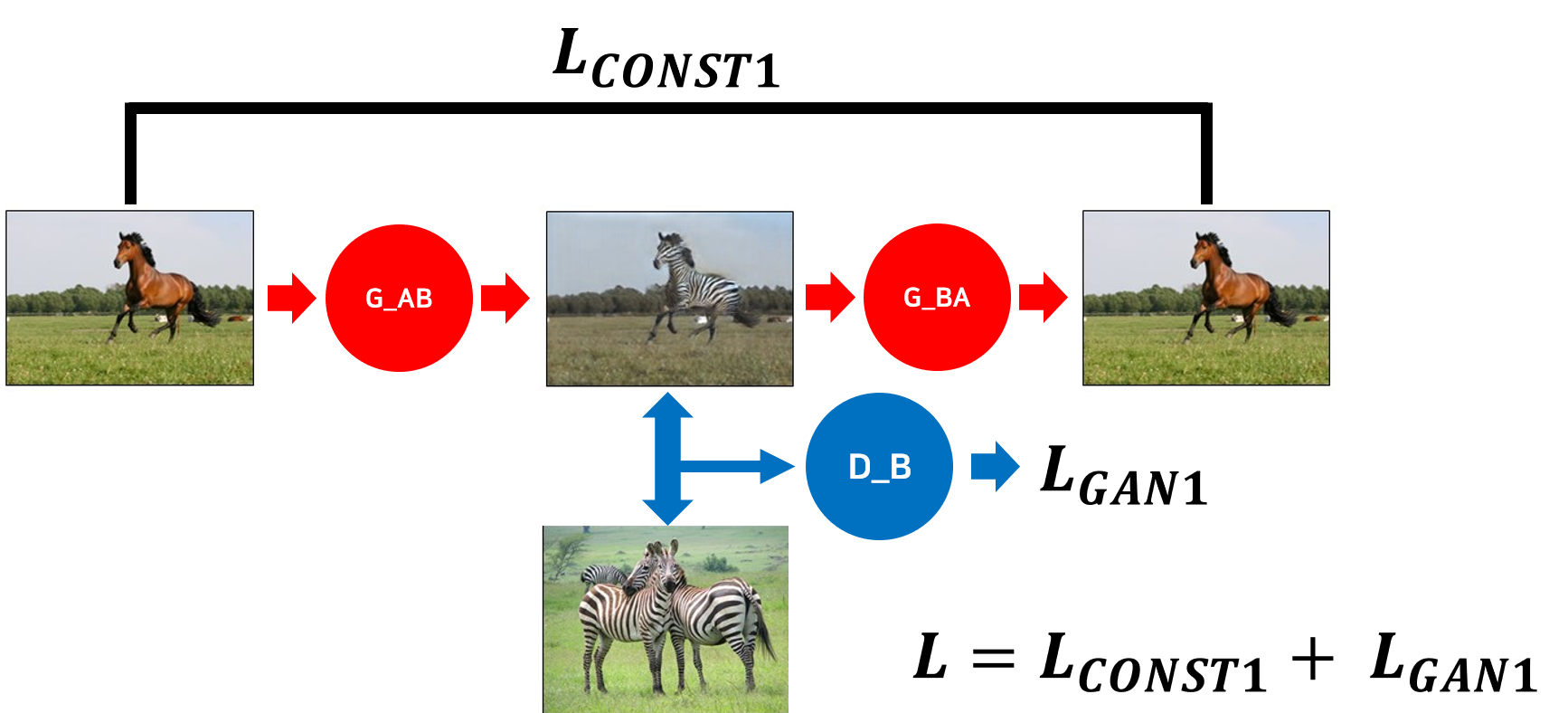
그림4에서 G는 Generator, D는 Discriminator를 의미한다. 뒤에 붙은 A,B는 A는 말, B는 얼룩말을 의미한다.
G_AB와 D_B를 보면 그냥 Pix2Pix와 별반 다르지 않음을 알 수 있다. G_AB는 말 데이터를 input으로 받아서 얼룩말의 데이터를 생성해 낸다. 그리고 D_B가 실제 얼룩말과 G_AB가 만들어 낸 가짜 얼룩말을 구분하는 학습을 함으로써 경쟁적인 학습이 가능해진다.
하지만 여기까지만 학습한다면 문제점이 발생한다. G_AB는 D_B가 구분할 수 없을 만큼 그럴듯한 ‘얼룩말’ 이미지를 생성해 낼 수는 있지만, ‘input과 같은 자세의 얼룩말’을 생성해 내지는 못한다. 아무도 G_AB에게 어떤 자세의 얼룩말을 생성해야 하는지 알려주지 않았다. Pix2Pix 처럼 Ground Truth 데이터가 존재하는 것도 아니기 때문이다. 그렇기 때문에 본 알고리즘에서는 G_BA라는 또 하나의 Generator가 등장한다. 방금 만든 얼룩말 이미지를 다시 말로 바꾸는 Generator이다. 잘 학습된 DiscoGAN이라면, 당연히 다시 생성된 말 이미지는 처음 넣어준 말 이미지와 동일해야 한다. 이 사실을 이용하여, input과 얼룩말이 되었다가 다시 되돌아 온 output 이미지 사이의 Loss를 전체 Loss에 추가해 주게 된다. 이러한 Loss를 Consistency Loss라고 한다. 이 때 Loss는 DiscoGAN의 경우 $L_2$-Loss를 쓰고 CycleGAN의 경우 $L_1$-Loss를 쓴다.
이렇게 Consistency Loss를 추가하게 되면 DiscoGAN은 말의 이미지를 함부로 아무 얼룩말 이미지로 바꿀 수 없다. 왜냐하면 다시 원본으로 돌아올 것 까지 생각해야 하기 때문이다. 그렇기 때문에 DiscoGAN은 input으로 받은 말 이미지에서 얼룩말처럼 보이게 만드는 데 필요한 최소한의 부분들만 수정한다. G_AB가 만들어낸 이미지가 얼룩말처럼 보여야 함과 동시에다시 처음으로 되돌아오기 용이해야 하기 때문이다. 그렇기 때문에 얼룩말로 바꾸는데 굳이 수정이 필요하지 않은 대상의 자세, 주변 배경 등이 유지되는 것이다.
뒤에 결과로 나오는 그림10에는 더 흥미로운 현상이 나타난다. 신발을 핸드백으로, 핸드백을 신발로 바꾸는 것인데, 신발→핸드백의 예를 들면 DiscoGAN은 신발을 input으로 받아 핸드백처럼 만듦과 동시에 신발이 원래 갖고 있던 색상이나 재질 등의 특성을 유지시켜서 다시 신발로 돌아오기 쉽도록 학습하였다. 그 결과 신발과 비슷한 스타일의 핸드백이 생성됨을 볼 수 있다.
이렇게 Consistency Loss를 추가해 주면 끝난 것 같지만, 사실 뒷편의 G_BA는 GAN을 구성하는 Generator임에도 불구하고 “당신이 생성한 이미지는 실제 말들과 구분할 수 없어야 해”라고 하는 GAN Loss가 존재하지 않는다. 또한 상식적으로 생각해도 말→얼룩말 알고리즘과 얼룩말→말 알고리즘이 대칭적인 구조여야 안정적인 학습이 가능해 질 것 같다. 그래서 그림5와 같은 구조를 만들어 그림4의 구조와 동시에 학습한다.
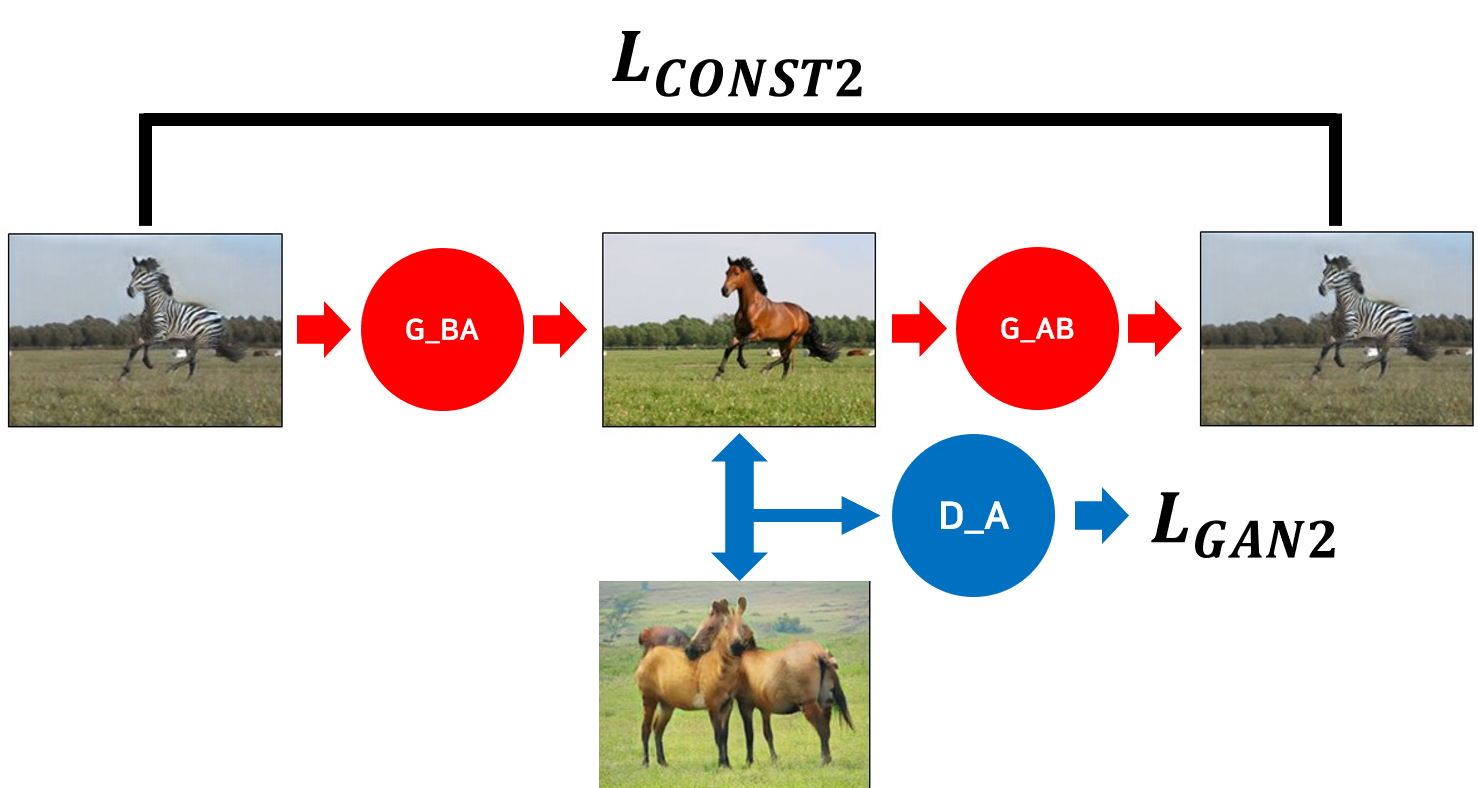
이로써 최종적인 Loss 식은 다음과 같게 된다.
$$L = L_ {CONST1} + L_ {GAN1} + L_ {CONST2} + L_ {GAN2}$$
Network Structure
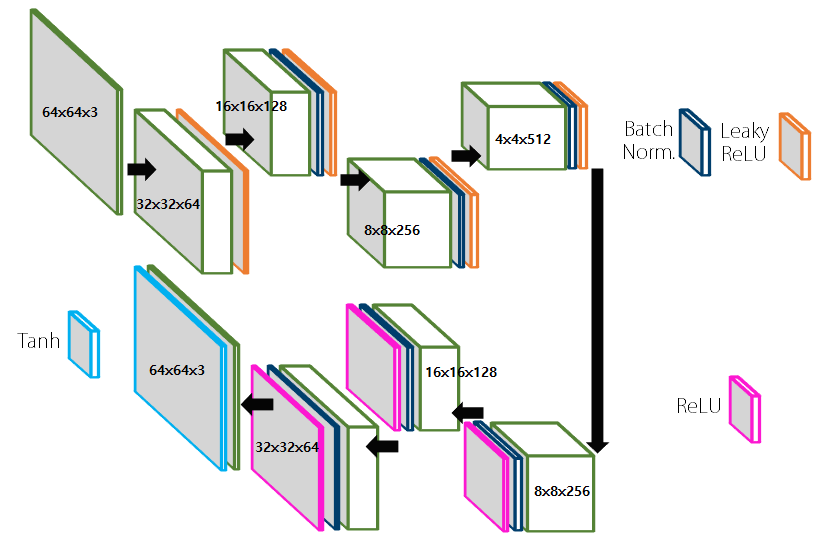
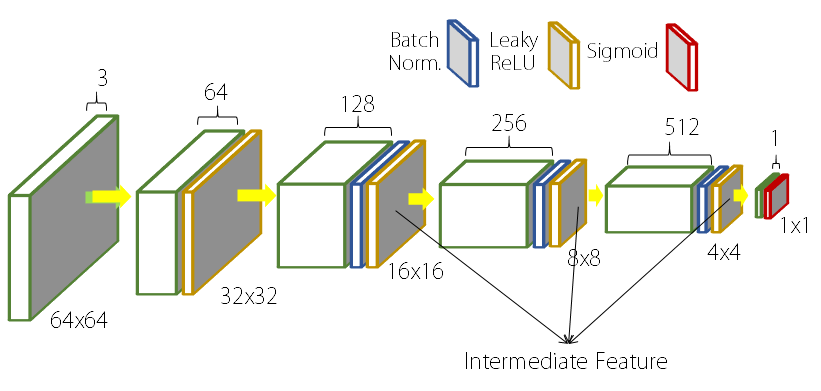
DiscoGAN의 결과
다음은 다양한 데이터들을 이용하여 DiscoGAN 학습을 진행한 결과이다. 왼쪽이 input, 오른쪽이 output이다.



