이전까지의 GAN 알고리즘들을 공부하면서 뭔가 답답함을 느끼신 분들이 계실 수도 있을 것 같습니다. GAN은 random noise를 input으로 하기 때문에 무작위의 데이터를 생성합니다. 그렇기 때문에 우리가 원하는 데이터를 얻을수도 없고, 어떤 데이터가 나올지 예측하는 일 조차 쉽지 않습니다. 그렇기 때문에 실생활 등에 적용하기에는 한계가 있습니다. 이번 포스트에서 다룰 Pix2Pix 알고리즘과 다음 포스트에서 다룰 DiscoGAN 알고리즘의 경우 이전의 알고리즘들과는 다르게 실제 Application에 바로 적용이 가능합니다.
Pix2Pix 알고리즘은 이미지의 Style을 변형시키는 알고리즘입니다. Image Translation이라고도 불리는데, 이름 그대로 언어로 따지면 번역으로 비유할 수 있습니다. 예를 들면 Edge 이미지로부터 원본 이미지를 복원하거나 흑백 이미지에 색을 입히는 Colorization도 Pix2Pix를 응용하면 구현이 가능합니다.
- 선수 지식: 이 포스트를 이해하기 위해서는 DCGAN에 대한 지식이 필요합니다.
- 참고 논문: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- 소스 코드: Tensorflow_Pix2Pix
Introduction
Pix2Pix는 random vector가 아니라 이미지를 input으로 받아서 다른 style의 이미지를 output으로 출력하는 알고리즘이며, 이를 학습시키기 위해서는 input으로 들어갈 dataset과 그 이미지들이 Pix2Pix를 거쳐서 나올 정답 이미지가 필요하다. 즉 Supervised Learning 알고리즘이다. GAN의 자랑거리 중 하나가 Unsupervised Learning라는 점인데, 너무 취약한 단점이 아닌가? 결론부터 말하면 아니다. 다음 예시를 보면 쉽게 알 수 있다.
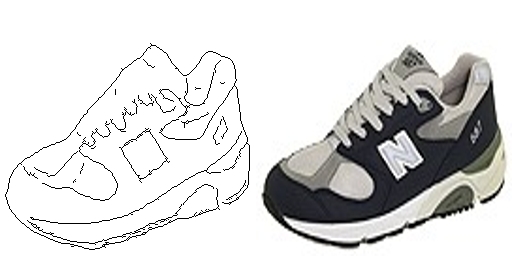
그림1은 Pix2Pix를 학습시키기 위한 dataset의 예시이다. 오른쪽은 평범한 운동화의 이미지이고, 왼쪽은 그 운동화의 Edge를 따 놓은 이미지이다. 이미지 처리를 공부해본 분들은 아시겠지만, 오른쪽의 운동화 이미지로부터 왼쪽의 Edge 이미지를 얻는 일은 굉장히 쉽다. 주어진 이미지로부터 Edge를 얻는 수많은 알고리즘들이 이미 존재한다. 그렇기 때문에 우리에게 그냥 운동화 이미지만 많이 있다면 얼마든지 위와 같은 Dataset을 만들 수 있다. 하지만 왼쪽의 Edge 이미지로부터 오른쪽의 원본으로 되돌아가는 일은 굉장히 어렵다. 이 어려운 일을 우리는 Pix2Pix에게 왼쪽의 Edge 이미지를 input으로, 오른쪽의 원본 이미지를 output으로 학습시킴으로써 해결할 수 있다는 것이다. Supervised Learning이 안좋은 이유는 dataset을 구축하기가 어렵다는 점인데, 위 특성에 따르면 Supervised Learning이기는 해도 dataset 구축이 어렵지 않다.
Network Structure
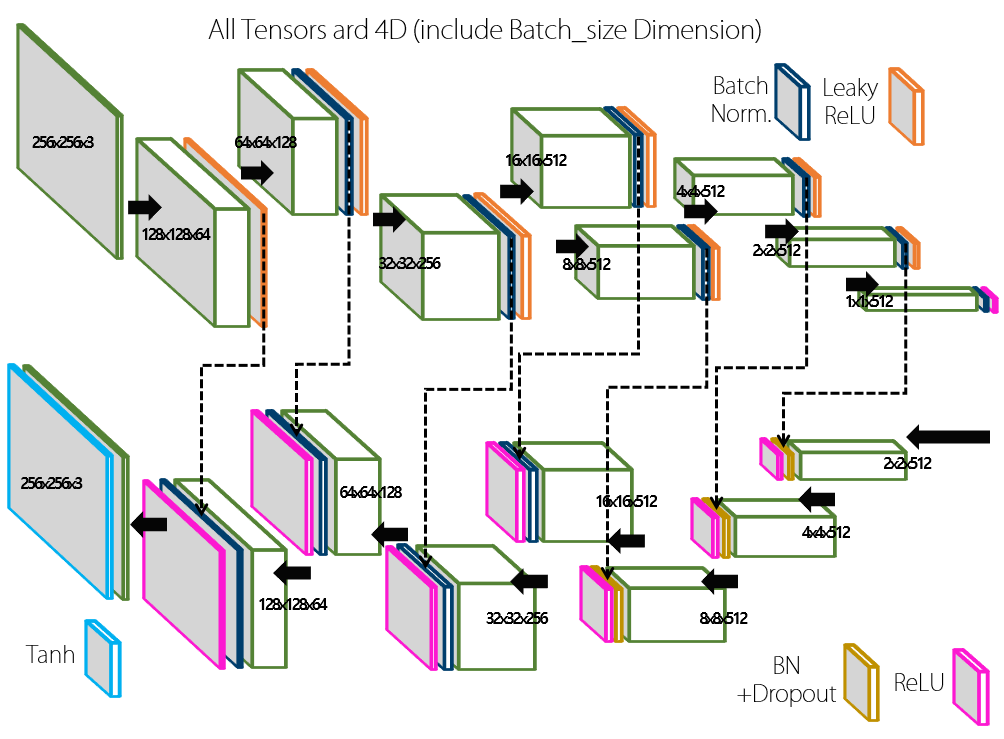
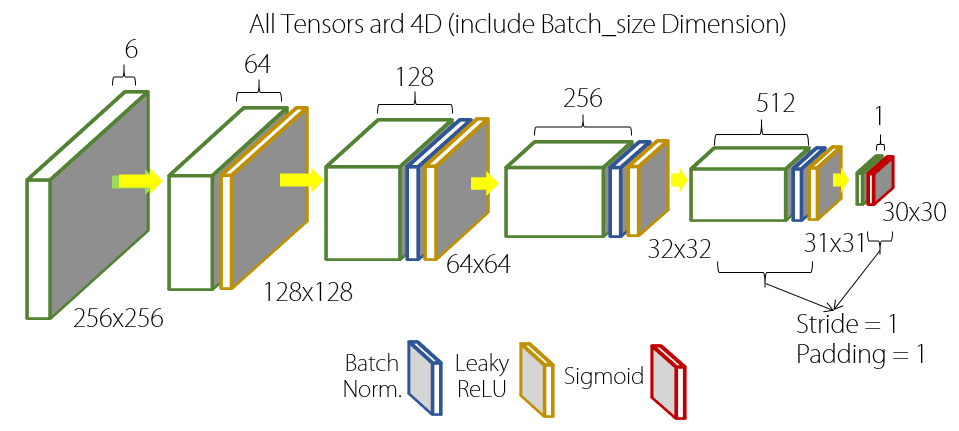
그림2와 그림3는 Pix2Pix 알고리즘의 Generator와 Discriminator이다. 얼핏 보기에는 복잡해 보이지만, 뒤에서 부분별로 살펴볼 것이다.
1. Generator
Pix2Pix의 Generator는 전체적인 구조가 일반적인 Generator 구조와는 다르다. 먼저 input과 output이 전부 이미지이기 때문에, 전체적으로 Size가 줄어들었다가 다시 커지는 구조를 갖는다. 일반적으로 이러한 네트워크 구조를 Encoder-Decoder 구조라고 부르는데 줄어드는 부분이 Encoder, 다시 커지는 부분이 Decoder에 해당한다. Size가 줄어들 때에는 DCGAN의 Discriminator와 마찬가지로 Stride가 2인 Convolution을 이용한다. 다시 커질 때도 역시 DCGAN의 Generator처럼 Transposed Convolution을 이용하게 된다. Output Layer의 Activation Function은 Hyperbolic Tangent로, -1~1 사이의 값을 갖는다. 그렇기 때문에 input 또한 -1~1 사이의 값으로 Normalize 해서 넣어 줘야 한다.
이제, 아까부터 Generator의 구조에서 계속 거슬렸을 저 점선 화살표들에 대해 알아 볼 차례다. 저 화살표들의 정체는 바로 Skip Connection이다. Generator의 구조를 보면 Encoder와 Decoder 부분이 완벽한 대칭 구조를 이루고 있기 때문에, Decoder의 각 output에 대해서 이에 대응하는 Encoder의 output이 존재한다. 이 사실을 이용하여 우리는 Encoder에서 각각 Acitvation Function을 거치기 전의 output 들을 복사하여 이에 대응하는 Decoder의 Activation Function을 거친 후의 output에 Concatnate한다. 즉, 그대로 뒤에 붙여주는 것이다. Encoder-Decoder 구조의 단점중의 하나가 바로, 중앙의 Feature Dimension이 input보다 작기 때문에 정보의 손실이 발생한다는 점이다. 그렇기 때문에 Pix2Pix의 output은 input보다 적은 정보만을 가지고 생성해야 하는 어려움이 따른다(input보다 정보가 많으면 많았지 적은 경우는 거의 없을텐데 말이다). 그렇기 때문에 Decoder의 각 Layer들에게 정보가 손실되기 전 Encoder단의 Feature들을 제공하여 참고하게 만드는 것이다. 이를 통해 더 선명한 형태의 output을 얻을 수 있다고 한다. 참고로 이렇게 Skip Connection이 추가된 Encoder-Decoder 형태의 네트워크를 U-Net 구조라고 한다.
2. Discriminator
Discriminator는 DCGAN과 마찬가지로 stride가 2인 Convolution Layer들로 구성되어 있다. 다만 뒤의 두 Layer의 경우 stride가 1인 Valid Convolution(Padding을 안하는 Convolution)을 통해 최종적으로 30by30의 output을 출력하는 모습을 볼 수 있다. 일반적인 Discriminator의 출력이 0~1 사이의 Scalar라는 점을 생각하면 분명 특이한 부분이다. 그 이유는 Discriminate를 이미지의 각 부분별로 진행하기 위함이다. 즉 이미지를 통째로 진짜인지 아닌지를 판별하는 것이 아니라, 이미지의 각 부분이 진짜인지 아닌지를 판별하도록 하는 것이다. 이를 통해 조금 더 디테일한 부분을 살린 이미지를 얻을 수 있게 된다.
Training Pix2Pix
지금까지 써 왔던 GAN의 Loss 함수는 다음과 같았다.
$$Loss_D = -\log(D(x)) -\log(1-D(G(z)))$$
$$Loss_G = -\log(D(G(z)))$$
하지만 Generator에게는 Discriminator를 속이는 일 말고도 하나의 과제가 더 주어지게 된다. 바로 Output으로 생성한 이미지가 미리 준비된 정답 이미지와 같아야 한다. 즉 예측과 정답 사이의 distance에 해당하는 Loss가 추가되어야 한다. 이 경우 Pix2Pix에서는 다음과 같이 $L_1$ Loss를 이용한다.
$$L_1(A,B) = \sum _ {x, y} \vert {A(x,y) - B(x,y)} \vert$$
그러므로 생성된 이미지 $G$와 정답 이미지 $Y$에 대하여 Generator의 Loss는 다음과 같이 수정된다.
$$Loss_G = -\log(D(G(z))) + L_1(G,Y)$$
Pix2Pix의 결과
다음은 다양한 데이터들을 이용하여 Pix2Pix 학습을 진행한 결과이다.
왼쪽부터 각각 input / output / groundtruth이다.

















