일반적인 DNN의 Fully Connected Layer들을 Convolution 연산으로 대체한 CNN(Convolutional Neural Network)는 각 픽셀들의 Spatial한 관계를 고려함으로 인해 이미지 인식에 대한 성능을 큰폭 상승시킨 바 있습니다. 이번 포스트에서는 GAN의 Layer 연산을 Transposed Convolution 연산으로 대체하여 이미지 생성에 관한 성능을 높인 DCGAN에 대해 알아보도록 하겠습니다. 이번 포스팅부터는 해당 알고리즘의 Tensorflow Source Code가 제공되니, 참고 부탁드립니다.
- 선수 지식: 이 포스트를 이해하기 위해서는 GAN과 Convolutional Neural Network에 대한 지식이 필요합니다.(수학적인 detail에 관한 지식은 필요 없습니다.)
- 참고 논문: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- 소스 코드: Tensorflow_DCGAN
Transposed Convolution
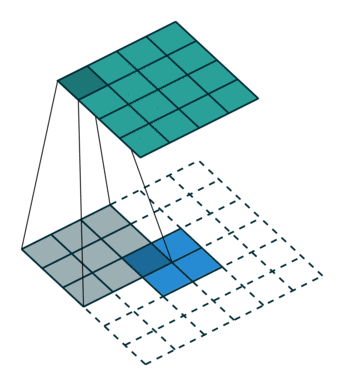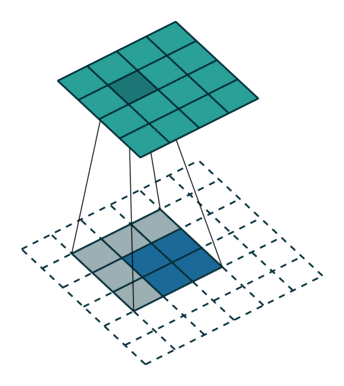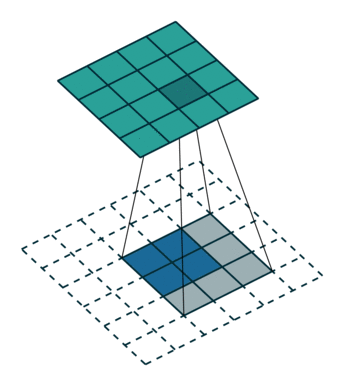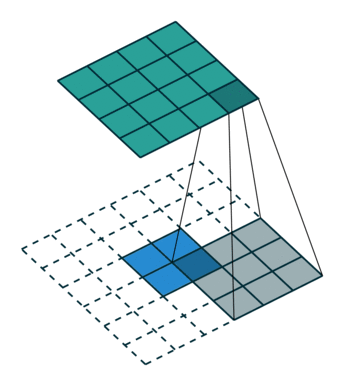
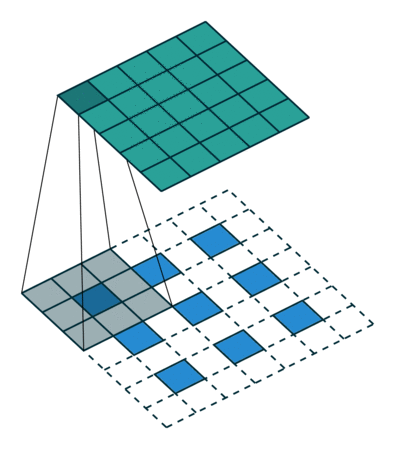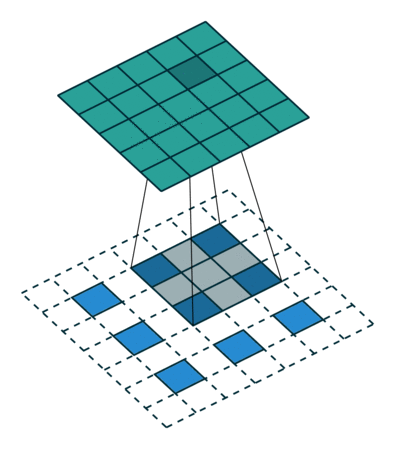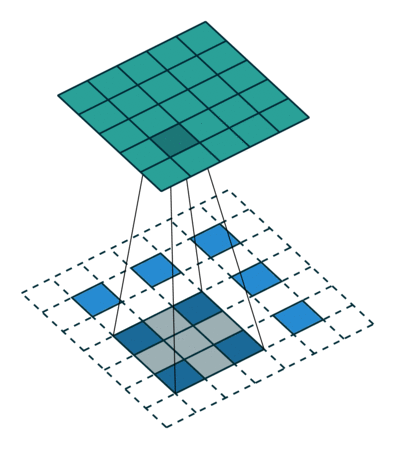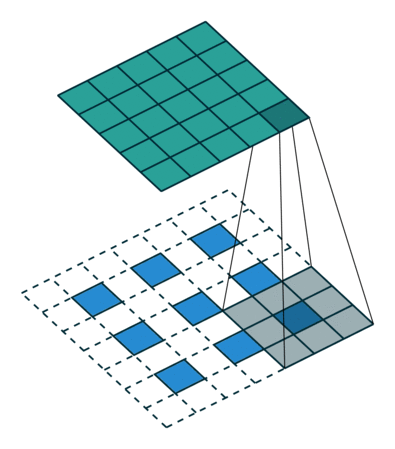
Convolution 연산은 Filter의 크기와 Stride에 따라서 이미지의 크기를 줄인다. Transposed Convolution은 Convolution과는 반대로 이미지의 크기를 키우는 역할을 하는 연산이다. Transposed Convolution 연산은 다음과 같은 과정을 통해 진행된다.
- input image에 Stride에 맞게(그림1과 2를 비교해보면 알 수 있다) Zero Padding을 추가한다.
- Zero Padding이 추가된 이미지에 Convolution 연산을 취한다.
Transposed Convolution의 원리가 완벽히 와 닿지 않아도 괜찮다. 구체적인 계산은 Tensorflow가 알아서 해 줄 것이므로, 대략적으로 ‘뭐 하는 연산인지’ 정도만 파악해도 괜찮다.
Deep Convolutional GAN
위에서 살펴 본 Transposed Convolution 연산을 통해 우리는 이미지 사이즈가 점점 커지는 형태의 Neural Network를 얻을 수 있다. 그러면 다음과 같이 CNN(Convolutional Neural Network)를 뒤집어놓은 모양의 네트워크를 얻을 수 있다.
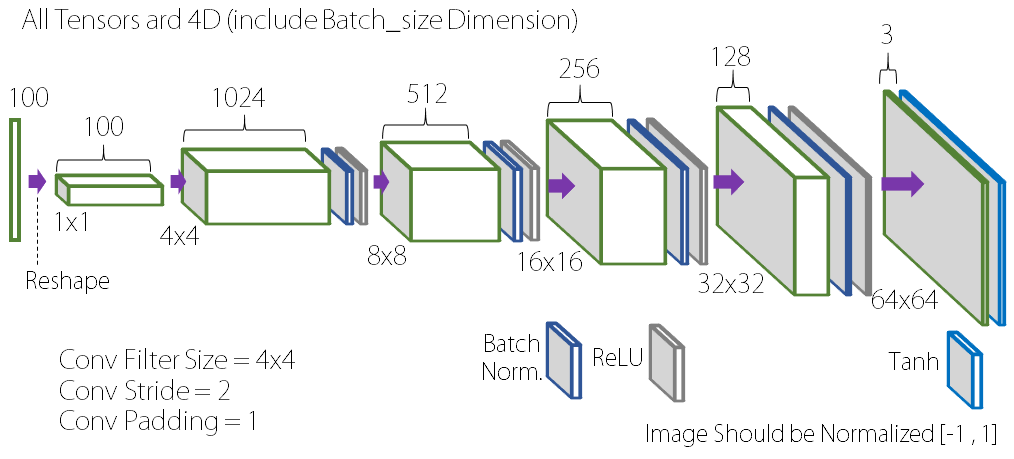
위와 같은 구조를 Generator로 사용하는 GAN을 우리는 Deep Convolutional GAN(DCGAN)이라고 한다. 그러면 Discriminator는 어떤 구조일까? Discriminator로는 Generator와 거의 완벽히 대칭을 이루는 CNN 구조를 이용한다. 다만, 일반적인 CNN과 다른 점은 Image Size가 줄어드는 방식이다. 일반적인 Classification을 위한 CNN 구조에서는 이미지 사이즈를 줄이기 위해 Pooling 방식을 사용하지만, DCGAN의 Discriminator는 Filter의 Stride를 1이 아닌 2로 하여 이미지 사이즈가 절반으로 줄어들게 만든다. Filter가 한 칸씩 이동하며 scan하는 것이 아니라 두 칸씩 이동하는 것이다.
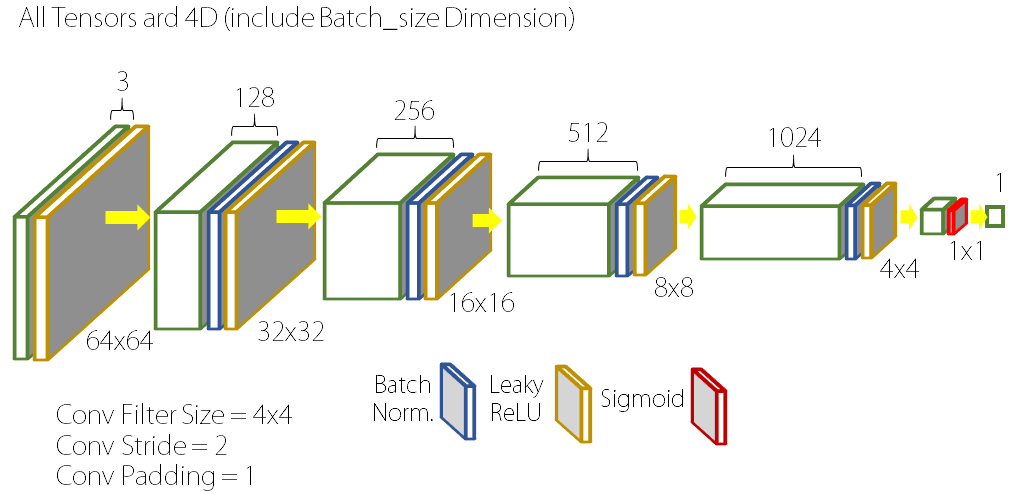
구체적인 구현 방법이 궁금하거나, 실제로 알고리즘을 돌려 보고 싶은 분들에게는 소스 코드를 참고하시길 추천드린다.
DCGAN의 결과
다음은 사람 얼굴 이미지인 CelebA 데이터베이스와 침실 이미지인 LSUN 데이터베이스로 DCGAN을 학습시켜 얻은 결과들이다.

