이번 포스트에서는 GAN의 기본 개념과 원리에 대해 알아보도록 하겠습니다.
GAN(Generative Adversarial Network)은 Generator와 Discriminator의 경쟁적인 학습을 통해 Data의 Distribution을 추정하는 알고리즘입니다. 여기서 Data의 Distribution은 쉽게 말하면 ‘어떻게 생겨먹었는가’를 의미합니다. 예를 들면, 사람 얼굴 이미지를 생성해 내는 알고리즘은 사람의 얼굴을 그럴듯하게 만들어 내기 위하여 ‘사람의 얼굴이 대충 어떻게 생겼는가’, ‘어떤 식으로 생겨야 사람 얼굴이라고 하는가’를 먼저 학습해야 할 필요가 있습니다. 이것을 바로 ‘사람 얼굴 이미지의 Distribution’이라고 할 수 있고, GAN은 그 것을 학습합니다.
- 선수 지식: 이 포스트를 이해하기 위해서는 ‘Deep Neural Network’의 개념에 대한 지식이 필요합니다.
- 참고 논문: Generative Adversarial Nets
- 소스 코드: golbin’s github
경찰과 지폐위조범
GAN은 Generative Model인 Generator(G)와 Discriminative Model인 Discriminator(D), 이렇게 두 Neural Network로 이루어져 있다. D의 목적은 ‘진짜 Data와 G가 만들어낸 Data를 완벽하게 구별해 내는 것’이고, G의 목적은 ‘그럴듯한 가짜 Data를 만들어내서 D가 진짜와 가짜를 구별하지 못하게 하는 것’이다. GAN 논문의 저자인 Ian Goodfellow는 D를 경찰, G를 지폐위조범에 비유하였다. 지폐위조범(G)이 위조지폐를 만들면, 경찰(D)은 위조지폐와 진짜 지폐를 구별해낸다. 지폐위조범은 갈수록 실제 지폐와 똑같이 생긴 지폐를 만들고자 할 것이고, 경찰은 갈수록 진짜 지폐와 위조지폐를 더 잘 구분하고자 할 것이다.
이렇듯 D와 G는 서로 경쟁적으로(Adversarially) 학습한다. G는 D를 어떻게 하면 잘 속일 수 있을지를 고민하며 학습하게 되고, D는 어떻게 하면 G에게 속지 않고 Data를 잘 구분할 지를 고민하며 학습하게 된다. D와 G는 이렇듯 경쟁하면서 실제로는 서로에게 학습의 방향성을 제시해주게 되어, Unsupervised Learning이 가능하게 된다. 라이벌이 생기면 서로가 서로를 이기기 위해 누가 시키지 않았는데도 자발적으로 더 치열하게 공부하는 모습이랄까…
GAN의 구조
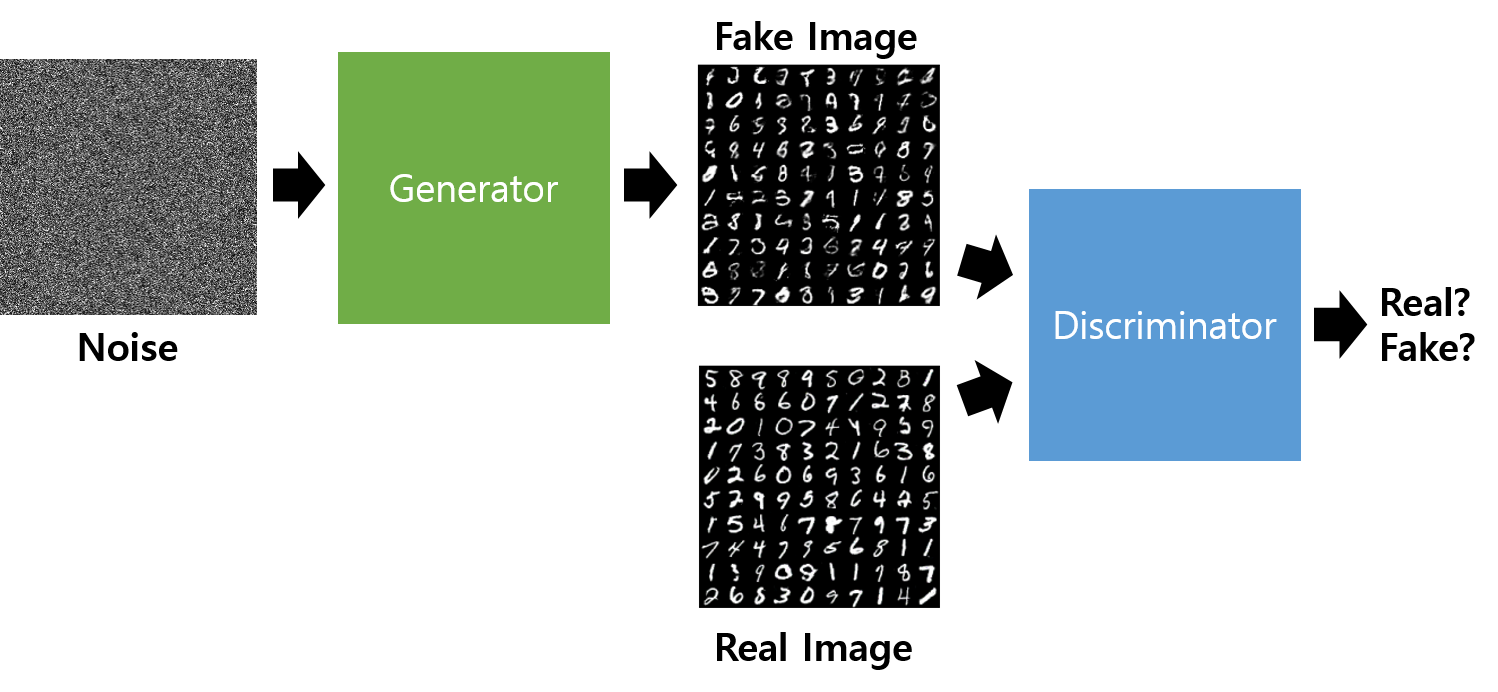
GAN을 학습시키기 위해 필요한 준비물은 Real Image이다(앞으로 이미지 처리의 예를 들 것이므로 이 data는 Image data라고 가정하자). 즉 G가 모방하게 할 실제 Data Set이 필요하다.
먼저, 우리는 G에게 줄 Random Noise를 생성하게 된다. 이 Noise는 G가 Fake Image를 만들 재료로 쓰이게 된다. 보통 Gaussian Distribution으로 Noise를 생성한다.
G는 이 Noise를 Input으로 받아, Neural Network를 거쳐 Fake Image를 생성하게 된다. 그리고 D는 Fake Image 또는 Real Image를 Input으로 받아 Neural Network를 거쳐 0과 1 사이의 값을 출력하게 되는데, 이 값은 D가 나름대로 판단한 ‘Input이 Real Image일 확률’이다. 즉, 이상적인 D는 Real Image를 받으면 1을, Fake Image를 받으면 0을 출력해야 한다.
자, 이제 G와 D의 주요 쟁점이 구체화되었다. 이를 수식으로 표현하기 전에 다음 쟁점을 기억하도록 하자.
- D는 자기가 Real Image를 받았을 때 1을 출력하고, Fake Image를 받았을 때는 0을 출력하기를 원한다.
- G는 자기가 만든 Fake Image를 D가 받았을 때 1을 출력하기를 원한다.
수식적 접근
수학적인 접근에 앞서서, 변수와 Notation들을 정리하고 넘어가자.
$x$ : Real Data.
$z$ : G가 Input으로 받는 Noise.
$G(z)$ : G 가 Noise를 받아서 생성해 낸 Fake Data.
$D(x)$ : D 가 Real Data를 받고 출력하는 값.
$D(G(z))$ : D 가 Fake Data를 받고 출력하는 값.
$\text{Error}(a,b)$ : $a$와 $b$ 사이의 Error. 즉 $a$와 $b$의 차이. 구체적인 식은 뒤에서 알아보도록 하자.
이제 위에서 정리했던 주요 쟁점을 그대로 수식으로 나타내보도록 하자.
먼저, D는 자기가 Real Image를 받았을 때 1을 출력하고, Fake Image를 받았을 때는 0을 출력하기를 원한다. 그러므로 D는 다음 식을 최소화시키기를 원한다.
$$Loss_D = \text{Error}(D(x),1) + \text{Error}(D(G(z)),0)$$
또한, G는 자기가 만든 Fake Image를 D가 받았을 때 1을 출력하기를 원한다. 그러므로 G는 다음 식을 최소화시키기를 원한다. 덧붙이자면, 아래 식에 $\text{Error}(D(x),0)$과 같은 항이 없는 이유는 G와 관계 없는 항이기 때문이다. 사실 D가 Real Image를 어떻게 판단하는지에 대해서는 G는 관심 없다.
$$Loss_G = \text{Error}(D(G(z)),1)$$
이제 $\text{Error}()$만 정해주면 되는데, 여기서는 다음과 같은 Cross-Entropy Error를 이용한다.
$$\text{Error}(p,t) = -t \log(p) - (1-t) \log(1-p)$$
$t$ : Ground Truth.
$p$ : Prediction.
그러므로 위 Loss 식들은 다음과 같이 계산될 수 있다.
$$Loss_D = -\log(D(x)) -\log(1-D(G(z)))$$
$$Loss_G = -\log(D(G(z)))$$
위 두 Loss를 Minimize하는 방향으로 D와 G를 학습시키면 되는 것이다. 생각보다 간단하다.
G를 위한 Adventage
사실 논문을 보면, Loss에 대한 식이 살짝 다르게 나와 있다. 먼저 Loss의 부호를 반대로 하고 이를 Maximize하는 방향으로 D의 식을 써보면 다음과 같아진다.
$$\max_ D \{ \log(D(x)) + \log(1-D(G(z))) \}$$
여기서, G는 사실 D가 Maximize 하고 싶어하는 것을 Minimize 하고 싶어하기 때문에 D와 G의 Loss를 다음과 같이 한 줄로 쓸 수 있다.
$$\min_ G \max_ D \{ \log(D(x)) + \log(1-D(G(z))) \}$$
이게 논문에서 나온 식인데, 우리가 위에서 구한 식과의 차이점은 바로 G가 $\log(1-D(G(z)))$를 Minimize 하느냐, $\log(D(G(z)))$를 Maximize하느냐에 있다. 사실 수식상으로는 차이가 있어도, $D(G(z))$가 0이 아닌 1에 가까워지는 방향을 지향한다는 점에서는 결과적으로 같다. 하지만 이 두 함수의 그래프를 보면 미세한 차이를 알 수 있게 된다.
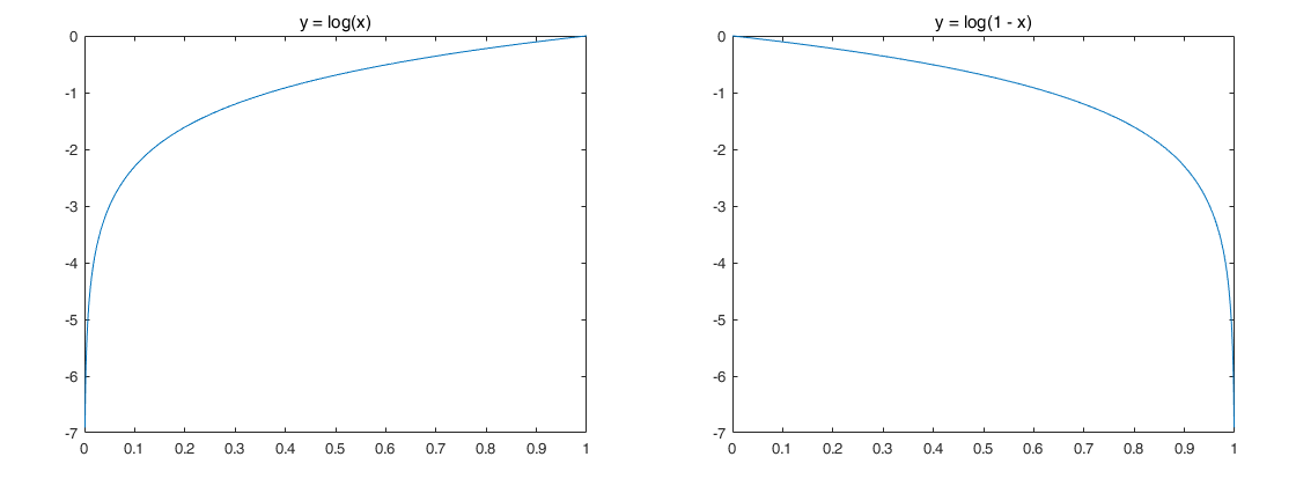
G는 처음에는 아무런 학습이 되지 않은 상태에서 Fake Image를 생성하기 때문에 초반에는 D가 매우 유리한 상태로 시작한다. 그래서 만약 이 엄청난 차이를 G가 극복하지 못한다면, D가 G를 영원히 압도하게 되는 현상이 발생할 수 있다. 그래서 우리는 Loss함수의 적절한 선택을 통해 G가 초반에 더 빠르게 학습할 수 있도록 도와주어야 한다.
우리는 그림 2의 왼쪽 함수를 Maximize하거나 오른쪽 함수를 Minimize 해야 한다. G는 초반에 D 입장에서 매우 구별하기 쉬운 Fake Image를 출력하기 때문에 $D(G(z))=0$에서 출발한다. 이 때, 왼쪽 함수를 Maximize 할 때가 오른쪽 함수를 Minimize할 때보다 초반에 더 급격한 변화를 이끌어낼 수 있다. 0 지점에서의 Loss 함수의 기울기 차이 때문이다.
그렇기 때문에 우리는 $\min_ G \max_ D \{ \log(D(x)) + \log(1-D(G(z))) \}$를 쓰지 않고, G와 D의 Loss를 달리 하여 우리가 위에서 구했던 대로 쓰게 되는 것이다.
$$Loss_D = -\log(D(x)) -\log(1-D(G(z)))$$
$$Loss_G = -\log(D(G(z)))$$
GAN의 결과물
그림 3은 GAN이 MNIST 데이터를 학습하는 과정에서 G가 만들어 낸 Fake Image들이다. 아래로 갈수록 학습이 더 진행된 결과이다.
